03-tidyr
2023-10-10
[ad] Data Science Student Society
Join DS3 at their Fall General Body Meeting to learn more about the events they’re offering this quarter, open board positions for the year, and free food! It will be happening on Wednesday (10/11) from 6-8pm, at PC Ballroom West

The Data: nycflights13
airlines: links airline to two letter codeairports: ID’ed by FAA codeplanes: ID’ed by tailnumairport: weather each hour; id’ed by two letter airport code
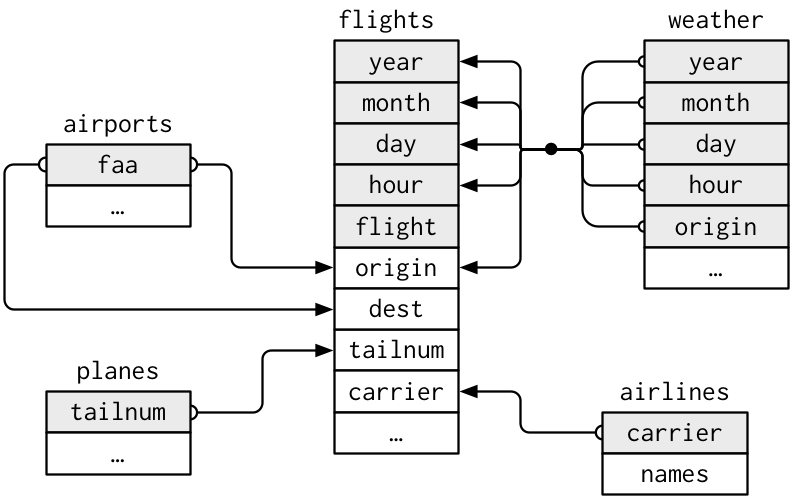
flightsconnects toplanesvia a single variable,tailnum.flightsconnects toairlinesthrough thecarriervariable.flightsconnects toairportsin two ways: via theoriginanddestvariables.flightsconnects toweatherviaorigin(the location), andyear,month,dayandhour(the time).
Mutating Joins
mutating joins - add new variables to a data frame from matching observations in another
For simplicity, we’ll work with only a handful of columns…
# A tibble: 336,776 × 7
year month day hour tailnum carrier name
<int> <int> <int> <dbl> <chr> <chr> <chr>
1 2013 1 1 5 N14228 UA United Air Lines Inc.
2 2013 1 1 5 N24211 UA United Air Lines Inc.
3 2013 1 1 5 N619AA AA American Airlines Inc.
4 2013 1 1 5 N804JB B6 JetBlue Airways
5 2013 1 1 6 N668DN DL Delta Air Lines Inc.
6 2013 1 1 5 N39463 UA United Air Lines Inc.
7 2013 1 1 6 N516JB B6 JetBlue Airways
8 2013 1 1 6 N829AS EV ExpressJet Airlines Inc.
9 2013 1 1 6 N593JB B6 JetBlue Airways
10 2013 1 1 6 N3ALAA AA American Airlines Inc.
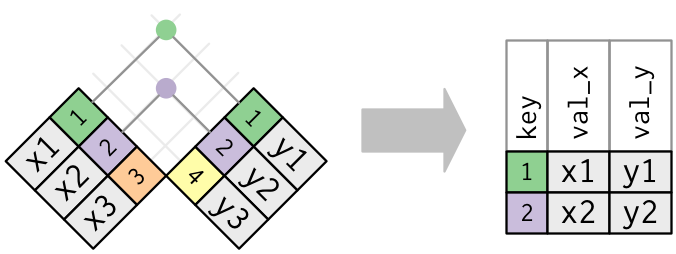
# ℹ 336,766 more rowsThere is now a new column name…coming from the airlines data frame.
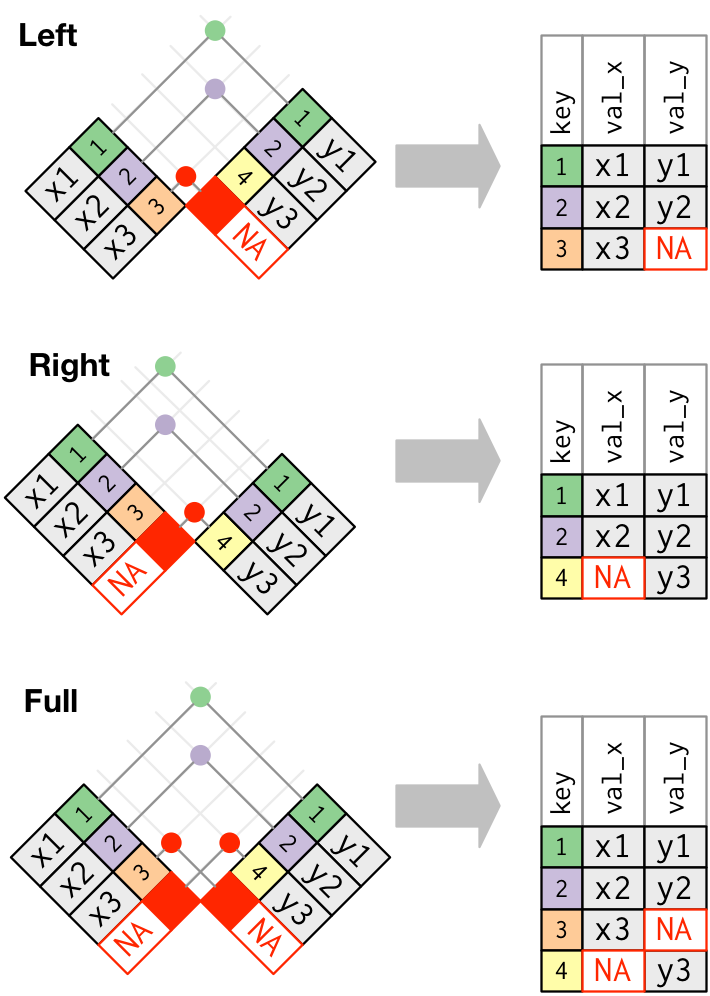
left_join:
- keeps all rows in first df (here:
flights) - adds all matching information from second df (here:
airlines); adds NAs for any observations not inairlines
Other joins:
right_join: keeps all observations in second df full_join: keeps all observations in either df
Recap
- Do you understand what constitutes tidy data?
- Can you identify what needs to be done to take a dataset from untidy to tidy?
- What is the difference been long data and wide data?
- Can I take long data to wide data? And wide to long?
- Can I carry out mutating joins on data?
![]()